️This article has been over 4 years since the last update.
本书主要介绍了一款开源CPU的前端设计,对Silicon领域或者计算机组成有兴趣的可以看一看。它是一本非常有价值的书,建议投入一定时间去精读。
注意: 本文作者并非硬件领域专家,而只是爱好者,因此本文是不可靠的。同时本文联想非常广泛,需要耐心阅读
在阅读本书前,需要补充如下知识
半导体制造流程
半导体行业是一个门槛高,周期长的行业,从设计图纸到最终手机中的芯片,主要有如下流程
- 前端(ASIC): 主要通过Verilog编写数字电路与高手编写模拟电路,最终通过EDA工具综合后生成网表(netlist),与编译器一样,主要是通过描述生成未经过优化的AST
- DFT: Design for test,用于为网表生成测试矢量,并加入测试电路
- 后端(COT): 对网表进行layout,布线,面积,Mask等设计(如果前端没做好,那么后端就要背锅了),最终生成GDS文件给Fabrication厂商
- 生产(MES): 通过Wafer/Bump/封装/Test等步骤,最终实现量产
本书主要讲的是【前端流程】中的【数字电路设计】的【CPU】设计,是半导体领域中的理论图纸设计阶段
时钟(CLK)
众所周知,CPU需要时钟“跳动”才能“实时”工作。在芯片中,主要采用锁相环(Phase-locked loop)实现高频时钟生成(Clock generator)
- 外频(主时钟): 通过晶振(quartz crystal oscillator)实现外部(比如主板)时钟生成,Quartz就是石英的意思,它有压电效应,实现高精度震荡。
- 倍频: 通过芯片内部的PLL电路实现,实现将外频分割(dividing the frequency)为更细的频率,这个是借助模拟电路实现负反馈动态调节,本文玩不转就不讲了。
最终时钟的总频率等于: 外频 * 倍频,我们在前端数字电路中只有理想的0和1,时钟跳动的快,工作速度上线就越高。当然在实际开发中,一般通过模拟器进行计算
- 通过EDA工具实现模拟(Simulation),速度较慢
- 通过Emulator集群进行模拟,速度较快,但是机器非常贵
- 甚至在《我的世界》游戏中,受限于红石的时钟速度,导致电路速度很慢。
引申到高层软件开发中,无论是异步Promise,事件驱动,还是消息队列,它内部一定有一个软件层次的时钟源(比如while或者第三方inoke)。在微服务作业中,我们有个叫做Quartz的开源定时任务,它本质也是定时发送时钟信号。翻看Flink的SourceFunction源码,它里面几乎都有一个while(true)实现采样生成数据源。
Verilog
Verilog是一种硬件描述语言,注意是对硬件的DSL描述(更类似Graphviz而不是Java)。编写者是数字电路Designer而不是Promgrammer,它虽然有for/if/always等高级实现,但是本质上silicon不可能实现for语句的,在专业开发中一般不推荐使用,而是用assign实现组合逻辑
在Mac下可以运行开源的iverilog进行编译Verilog文件
1 | brew install icarus-verilog |
或者使用Windows下的ModelSim/Eclipse进行查看
对于新语言,我建议第一步先找个IDE拐棍,然后上源码进行入门 。看完上面后,再看一些
How CPU works的视频加深理解
背景
基本术语
- CPU: 目前的CPU在大部分情况下均指SOC,除了处理器本身还包括额外的IP/KGD(Known good die)
- Instrcution: 指令,也就是“字节码”结构体,一般由
PC+操作数+参数构成,被硬件进行Decode为AST并执行 - ISA: 指令集架构(Instrcution Set Architecture/ˈɑrkɪˌtɛktʃɚ/),主要有以x86为代表的CISC(Complex Instruction Set Computer)与R(educed)ISC,现在的嵌入式硬件主要是RISC架构
- 32与64位: 指通用寄存器的的宽度(越长越好),而非指令长度(越短越好,甚至可以压缩)
关于ARM
ARM主要有两种授权方式
| 纯IP核 | ARM架构 | |
|---|---|---|
| 授权方式 | 起步价便宜,后续按片收费 | 起步价贵,买断,后续不收费 |
| 研发成本 | 低,把现成IP拿来用 | 高,耗时长,需要自己实现,可以看作自主研发 |
| 代表厂商 | 小厂商 | Hisilicon等,一般用于高端产品 |
目前大厂除了使用ARM架构,也会自研架构,但是问题还是在生态上
关于RISC-V
RISC-V(读作Risk-five)是一款Berkeley诞生开源硬件,本书的蜂鸟V200是经过业界工程师的专业设计,本书主要就是讲这个设计。作者的观点非常明确:适用于低功耗嵌入式场景中,尽可能设计简洁的指令与架构,而将复杂逻辑移动到编译器优化与库函数中,以降低硬件复杂度。
流水线(Pipeline)
本质上CPU也是一个解释器,在CPU中有流水线,与富士康的流水线一样,通过分配工作给专职模块,用空间换时间,尽可能实现每个时钟周期每个电路都在连续不断工作,提高面积利用效率。
before, 由于电路耦合在一起,需要60个单位的时间执行这个长指令
1 | INPUT -> 逻辑组(60) -> OUTPUT |
after,通过分工,实现20个周期即可完成计算(代价是面积更大/设计更复杂)
1 | INPUT -> 逻辑组(20) -> 寄存器 -> 逻辑组(20) -> 寄存器 --> 逻辑组(20) -> OUTPUT |
每个逻辑计算需要时间,比如某个复杂逻辑耗时为60个时钟,通过3层流水线设计后,可以将耗时降低到20个时钟(理论计算),进而提高工作主频。
CPU流水线的设计思路与软件中的函数式编程(比如Flink/RxJava)是一样的,区别是CPU依赖时钟提供信号,而软件中抽象成了Batch/Stream概念;
下面以硬件,大数据与前端技术进行类比,它们都是将单个复杂任务分而治之,最终合并的设计。
| CPU | 分布式计算(以Flink为例) | Jenkins Pipeline | |
|---|---|---|---|
| 数据源 | 时钟信号 | SourceFunction(通过轮询poll实现,有Interval) | SCM Pull轮询 |
| 流水线 | 多级电路,提高计算主频 | 函数式编程,提高计算主频 | CSP |
| 代价 | 牺牲面积/分支预测 | 部署/合并难度 | 牺牲可读性 |
| 信道 | Register | Akka MailBox | Curry |
软硬件的很多思想是融合贯通的,通过整理思考,可以提高自己知识的广度。很多前端的新技术,在硬件看来实际上就是炒冷饭(比如前端的Prelink预加载技术在硬件中就是分支预测)。学习完新的知识后,一定要总结固化,否则后期就学不动了。
经典的RISC流水线(Classic RISC pipeline)
步骤: Instruction fetch, decode, execution, memory access and write register back.
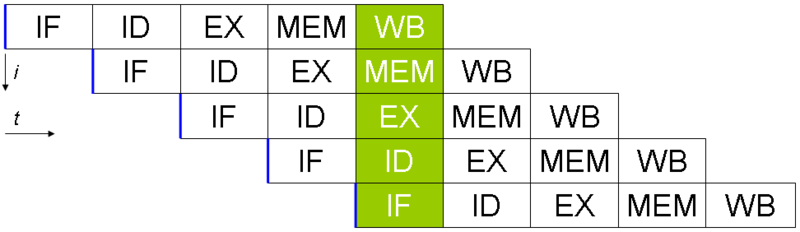
分支预测单元(Branch Prediction Unit)
分支预测指在带条件的jump指令时,由于流水线中下一个指令到底跳转到哪还在计算中,猜不出接下来执行的指令是什么,如果此时暂停等待跳转结果,那么流水线周期就浪费了。对于此问题,可以使用分支预测(Brach Prediction)来判断下一步跳转的方向与地址,先执行了再说,万一猜对了就赚了。
我们取一个常见的例子,当我们在运行如下代码时,可以发现Arrays.sort是否进行对下面循环的速度有较大的影响,这是由于data[c] >= 128是完全随机的,导致CPU无法预判下一步指令到底是什么,导致性能变差。
1 | // Generate data |
分支预测有很多种类,比如
- 默认认为不会跳转,直接执行下一个指令(最偷懒的实现)
- 默认执行PC数向下跳转的指令(优化for循环)
- 通过硬件HashMap动态维护缓存(高级处理器实现)
而在RISC-V中,采用是较为简单的第二种预测,它默认循环中不会有复杂的判断
分支预测优化
通过上面的例子,可以发现在写高性能代码时也是有讲究的,特别是嵌入式软件(Java不涉及)
- 高耗时任务中尽可能写连续的指令,不要用if等条件跳转语句(而换成HashJoin等类似方法)
- 模式匹配中,尽可能将可能性更高的条件放到前面
- 通过一些宏
#define likely(x)帮助编译器生成更好的汇编代码(一般要开到O2)
上述优化可能牺牲代码的可读性,因此分支预测优化仅限于核心模块
敏捷项目的分支预测
可能很多人都看过一张很著名的图,客户需要一个秋千,最终研发实际交付了一个轮胎。在软件开发中,传统的瀑布(waferfall)方法论是整体进行,此迭代速度较慢,因为一个周期下需要干一堆事情
1 | <------------------- 30days ------------------> |
对此,项目中引入了敏捷开发(Agile software development),也就是将任务拆解为多次小迭代(small sprints)。
1 | <------------------- 30days ------------------> |
其实这里也是通过多级流水线与分支预测的结合,只不过这里的分支预测的实现不是电路,而是开发人员的项目管理经验。如果能力不够或者客户配合不够,就成了“假敏捷”了。
Agile并不能改善代码质量,核心还是在流水线的实现上
本书主要就是看了流水线的实现,其它的也看不懂,就写到这吧
广告
目前半导体行业极其缺少即懂业务又懂软件的开发,在各大厂裁员的情况下,半导体(夕阳)行业发展仍然非常迅速。如果你比较热爱持续改进,领域驱动设计,数据仓库建设,机器识别,Java等技术,有机会与制造专家合作设计功能,可以联系本人内推,加入国内第一IC厂商且有HC号。
APPENDIX
- 使用JS实现的RISV与Linux: https://bellard.org/jslinux/